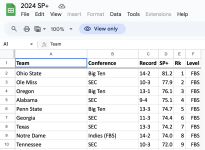
I'll also say that Bill Connelly himself acknowledges that early in the season sample sizes are too small to yield accurate results. Most of us on this thread understand this, except for one poster it seems.
Here's Connelly below, sarcastically responding to a poster who criticized his early season model results after only 4 games.
View attachment 337710
Bottom line, algorithmic models need a meaningful amount data to be accurate. The data is scarce early in the season as teams haven't played each other to necessary level.
Sure his model uses other, off the field metrics like recruiting, previous years results, etc. But using those metrics assumes that Connelly can accurately assess those metrics, weight them properly, not miss other metrics, etc. There's little reason to assume he has properly identified, assessed and weighted the correct off-field metrics.
Using previous years results was likely more relevant in pre-NIL and portal times. Now, teams can flip their fortunes in the span of one single year rendering previous years results less predictive.
The best data source is on-field results, which accrues over the course of the season. By week 12 I expect Sp+ (and FPI) to cluster around the human polls. That's what usually occurs with these models. But early in the season the models aren't particularly meaningful as Connelly himself acknowledges above